AlphaZero : l'IA de Google DeepMind devient imbattable aux échecs
Par Marc Zaffagni
Journaliste
Publié le 07/12/2017
DeepMind, filiale de Google, a fait une nouvelle démonstration des performances de son programme d'intelligence artificielle. AlphaZero, une variante d'AlphaGo qui pratique l'apprentissage par renforcement, n'a mis que quatre heures en partant des règles de base pour vaincre le meilleur programme de jeux d'échecs actuel.
Après avoir démontré l'implacable supériorité de son intelligence artificielle (IA) au jeu de go, DeepMind, filiale de Google, cherche désormais à rendre celle-ci plus généraliste. L'objectif est de créer une IA réussissant à accomplir des tâches complexes dans le monde réel avec un minimum de connaissances a priori. Pour cela, il faut que le programme puisse évoluer de manière autonome sans s'appuyer sur un apprentissage supervisé par des humains.
Il y a peu, DeepMind a fait un pas important dans cette direction avec AlphaGo Zero, une nouvelle version de son programme de jeu de go qui n'a mis que trois jours à vaincre son prédécesseur en pratiquant un apprentissage « tabula rasa » par renforcement (reinforcement learning, en anglais). AlphaGo Zero ne disposait que des règles du jeu et de la position des pierres sur le plateau. Partant de cette base, elle est allée encore un peu plus loin.
Dans un nouvel article scientifique, DeepMind dévoile ainsi AlphaZero, qui reprend le principe de l'apprentissage autodidacte par renforcement dans une approche moins spécialisée. En disposant pour seule base des règles des jeux d'échecs, de go et de shogi (variante japonaise des échecs), cette IA est parvenue à atteindre un « niveau de jeu surhumain » et à battre les meilleurs programmes existant dans ces trois disciplines.
AlphaZero a battu Stockfish en quatre heures.
La performance est d'autant plus impressionnante qu'il lui aura fallu moins de vingt-quatre heures pour y parvenir : après huit heures d'entraînement et 21 millions de parties jouées contre lui-même, AlphaZero a battu AlphaGo-Lee, la première IA à avoir dominé un joueur humain.
AlphaZero n'a eu besoin que de quatre heures de pratique et 44 millions de parties pour vaincre Stockfish, l'un des meilleurs moteurs d'échecs actuels.
Deux heures et 24 millions de parties lui suffirent pour terrasser Elmo, le meilleur programme de shogi.
Cette polyvalence et cette rapidité rapprochent encore un peu plus DeepMind et Google de leur objectif : créer une intelligence artificielle généraliste susceptible de travailler dans des domaines concrets, notamment pour la science et la médecine.
Google en retirerait aussi beaucoup d'avantages pour faire évoluer ses propres services. Le prochain grand défi pour DeepMind et sa maison mère sera de pouvoir battre les humains au jeu vidéo StarCraft.
Au bout de seulement trois jours, le programme a pulvérisé AlphaGo Lee, le logiciel qui avait battu le champion Lee Sedol, en gagnant 100 victoires à 0. Après 21 jours d'auto apprentissage, AlphaGo Zero était au niveau d'AlphaGo Master, la version qui a vaincu le numéro 1 mondial Ke Jie en mai dernier. Et 40 jours après le début de son entrainement, AlphaGo Zero a surpassé toutes les versions existantes pour devenir tour simplement le meilleur joueur de go de la planète.
Un apprentissage « tabula rasa »
La principale différence technique entre AlphaGo Zero et ses prédécesseurs est qu'il se base uniquement sur la technique d'apprentissage par renforcement (reinforcement learning). Les autres AlphaGo combinaient cette méthode avec de l'apprentissage supervisé alimenté par des parties de référence jouées par des humains.
Par ailleurs, AlphaGo Zero n'utilise plus qu'un seul réseau neuronal d'apprentissage profond contre deux précédemment. Auparavant, les logiciels de DeepMind associaient un « réseau de décision » qui décidait du prochain mouvement à jouer à un « réseau de valeur » qui prédisait le vainqueur de la partie à partir des positions en cours sur le plateau. AlphaGo Zero a fusionné ces deux réseaux neuronaux pour gagner en efficacité et il n'a même plus besoin de jouer des parties aléatoires rapides pour prédire l'issue du jeu.
« Cette technique est plus puissante que les versions précédentes d'AlphaGo car elle n'est plus contrainte par les limites de la connaissance humaine. Au lieu de cela, elle est capable d'apprendre en partant d'une feuille blanche avec le joueur le plus fort du monde : AlphaGo lui-même », explique DeepMind sur son blog.
Ce graphique nous montre la courbe d’apprentissage d’AlphaGo Zero qui n’a mis que trois jours à battre AlphaGo Lee et 40 jours pour s’imposer comme le meilleur joueur du monde. © DeepMind
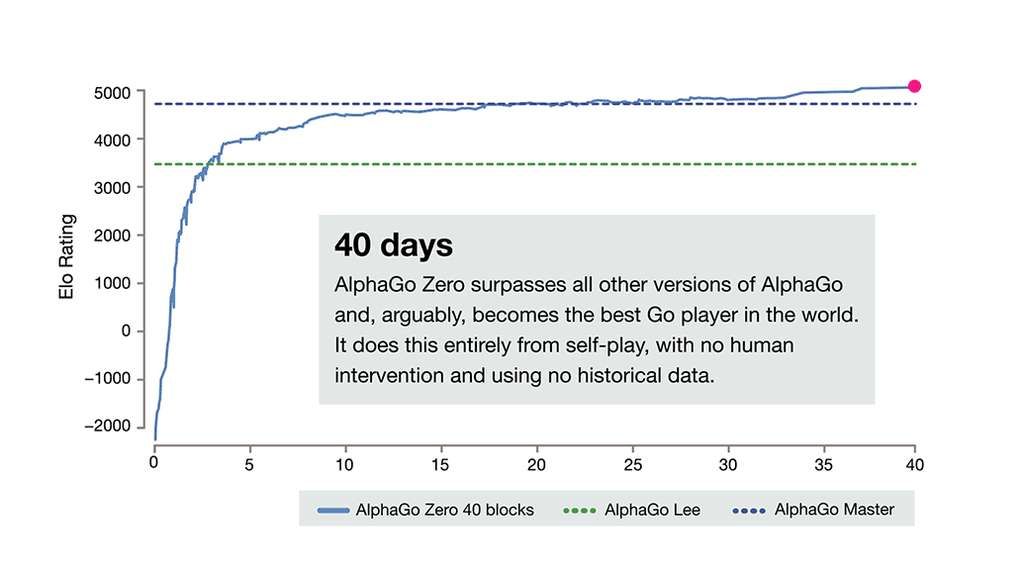
Ce graphique nous montre la courbe d’apprentissage d’AlphaGo Zero qui n’a mis que trois jours à battre AlphaGo Lee et 40 jours pour s’imposer comme le meilleur joueur du monde. © DeepMind
AlphaGo Zero a fait preuve de créativité
Non content d'être devenu imbattable en partant d'informations minimales, AlphaGo Zero a impressionné ses créateurs par sa capacité à s'approprier le jeu. Après avoir assimilé les bases et reproduit sans aide extérieure les stratégies de jeu élaborées par les humains depuis des milliers d'années, le programme est allé plus loin en créant des ouvertures totalement inédites. AlphaGo Zero a littéralement inventé de nouvelles formes de jeu, tout cela en l'espace de quelques jours.
Selon DeepMind, de telles capacités ouvrent des perspectives prometteuses pour la création d'IA capables de travailler dans des domaines concrets : santé, consommation d'énergie, science des matériaux. « Vous avez un agent [une IA, NDLR] qui peut être transposé du jeu de go à n'importe quel autre domaine (...). Vous obtenez un algorithme qui devient si généraliste qu'il peut être appliqué n'importe où », estime David Silver, chercheur en chef sur AlphaGo.